Minimum effort adaptation of automatic speech recognition system in air traffic management
Mrinmoy Bhattacharjee, Petr Motlicek, Srikanth Madikeri, Hartmut Helmke, Oliver Ohneiser, Matthias Kleinert, Heiko Ehr
European Journal of Transport and Infrastructure Research
[+Abs]
[HTML]
[PDF]
[+Bibtex]
Advancements in Automatic Speech Recognition (ASR) technology is exemplified by ubiquitous voice assistants such as Siri and Alexa. Researchers have been exploring the application of ASR for Air Traffic Management (ATM) systems. Initial prototypes utilized ASR to pre-fill aircraft radar labels and achieved a technological readiness level before industrialization (TRL6). However, accurately recognizing infrequently used but highly informative domain-specific vocabulary is still an issue. This includes waypoint names specific to each airspace region and unique airline designators, e.g., “dexon” or “pobeda”. Traditionally, open-source ASR toolkits or large pre-trained models require substantial domain-specific transcribed speech data to adapt to specialized vocabularies. However, typically, a “universal” ASR engine capable of reliably recognizing a core dictionary of several hundreds of frequently used words suffices for ATM applications. The challenge lies in dynamically integrating the additional region-specific words used less frequently. These uncommon words are crucial for maintaining clear communication within the ATM environment. This paper proposes a novel approach that facilitates the dynamic integration of these new and specific word entities into the existing universal ASR system. This paves the way for “plug-and-play” customization with minimal expert intervention and eliminates the need for extensive fine-tuning of the universal ASR model. The proposed approach demonstrably improves the accuracy of these region-specific words by a factor of ≈7 (from 10% F1-score to 70%) for all rare words and ≈5 (from 13% F1-score to 64%) for waypoints.
@article{Bhattacharjee_Motlicek_Madikeri_Helmke_Ohneiser_Kleinert_Ehr_2025, title={Minimum effort adaptation of automatic speech recognition system in air traffic management}, volume={24}, url={https://journals.open.tudelft.nl/ejtir/article/view/7531}, DOI={10.59490/ejtir.2024.24.4.7531}, number={4}, journal={European Journal of Transport and Infrastructure Research}, author={Bhattacharjee, Mrinmoy and Motlicek, Petr and Madikeri, Srikanth and Helmke, Hartmut and Ohneiser, Oliver and Kleinert, Matthias and Ehr, Heiko}, year={2025}, month={Jan.}, pages={133–153} }
Exploration of Speech and Music Information for Movie Genre Classification
Mrinmoy Bhattacharjee, S. R. Prasanna Mahadeva, Prithwijit Guha
ACM Transactions on Multimedia Computing, Communications, and Applications
[+Abs]
[HTML]
[PDF]
[+Bibtex]
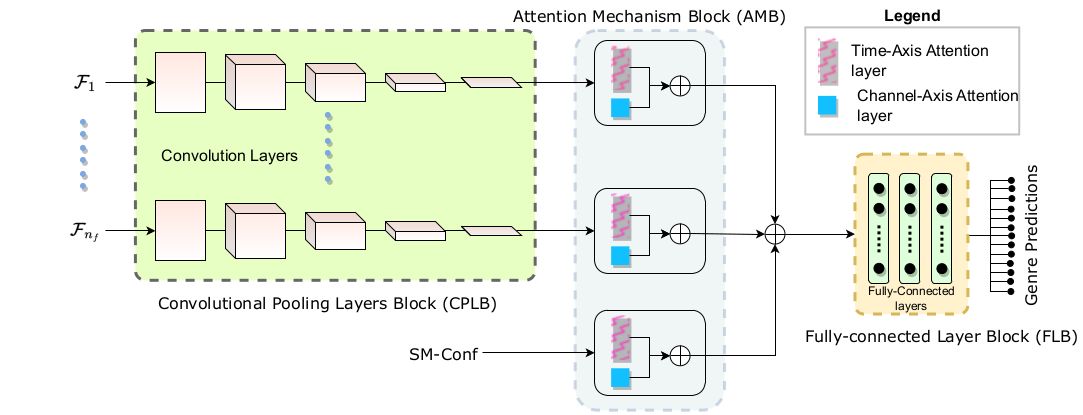
Movie genre prediction from trailers is mostly attempted in a multi-modal manner. However, the characteristics of movie trailer audio indicate that this modality alone might be highly effective in genre prediction. Movie trailer audio predominantly consists of speech and music signals in isolation or overlapping conditions. This work hypothesizes that the genre labels of movie trailers might relate to the composition of their audio component. In this regard, speech-music confidence sequences for the trailer audio are used as a feature. In addition, two other features previously proposed for discriminating speech-music are also adopted in the current task. This work proposes a time and channel Attention Convolutional Neural Network (ACNN) classifier for the genre classification task. The convolutional layers in ACNN learn the spatial relationships in the input features. The time and channel attention layers learn to focus on crucial timesteps and CNN kernel outputs, respectively. The Moviescope dataset is used to perform the experiments, and two audio-based baseline methods are employed to benchmark this work. The proposed feature set with the ACNN classifier improves the genre classification performance over the baselines. Moreover, decent generalization performance is obtained for genre prediction of movies with different cultural influences (EmoGDB).
@article{10.1145/3664197, author={Bhattacharjee, Mrinmoy and S. R., Prasanna Mahadeva and Guha, Prithwijit}, title={Exploration of Speech and Music Information for Movie Genre Classification}, year={2024}, issue_date={August 2024}, publisher={Association for Computing Machinery}, address={New York, NY, USA}, volume={20}, number={8}, issn={1551-6857}, url={https://doi.org/10.1145/3664197}, doi={10.1145/3664197}, journal={ACM Trans. Multimedia Comput. Commun. Appl.}, month={jun}, articleno={241}, numpages={19}}
Contextual Biasing Methods for Improving Rare Word Detection in Automatic Speech Recognition
Mrinmoy Bhattacharjee, Iuliia Nigmatulina, Amrutha Prasad, Pradeep Rangappa, Srikanth Madikeri, Petr Motlicek, Hartmut Helmke, Matthias Kleinert
49th IEEE International Conference on Acoustics, Speech, & Signal Processing (ICASSP)
[+Abs]
[HTML]
[PDF]
[+Bibtex]
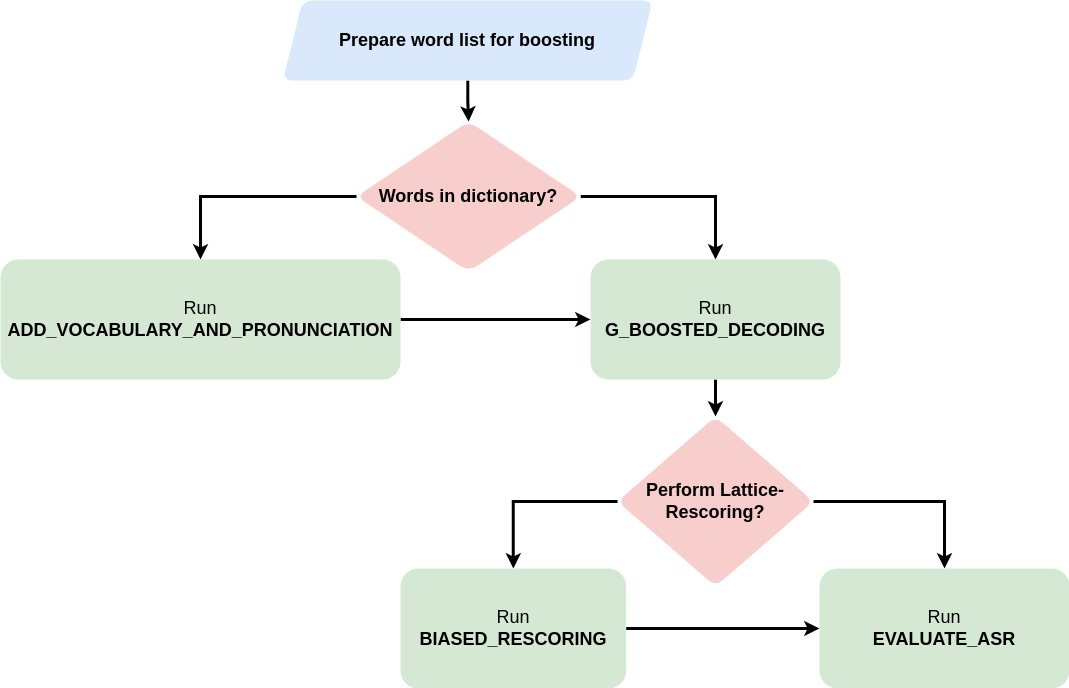
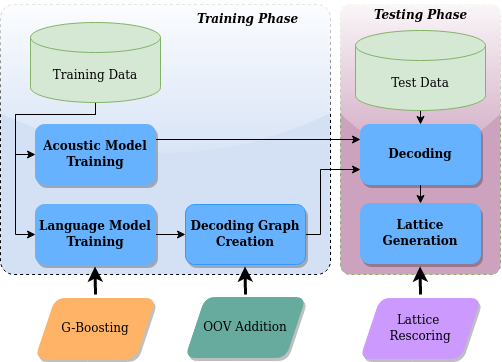
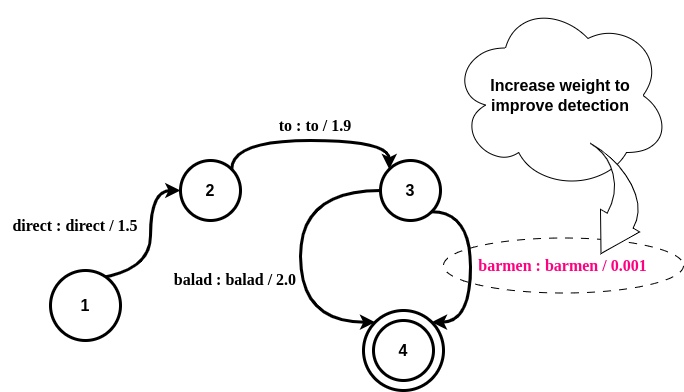
In specialized domains like Air Traffic Control (ATC), a notable challenge in porting a deployed Automatic Speech Recognition (ASR) system from one airport to another is the alteration in the set of crucial words that must be accurately detected in the new environment. Typically, such words have limited occurrences in training data, making it impractical to retrain the ASR system. This paper explores innovative word-boosting techniques to improve the detection rate of such rare words in the ASR hypotheses for the ATC domain. Two acoustic models are investigated: a hybrid CNN-TDNNF model trained from scratch and a pre-trained wav2vec2-based XLSR model fine-tuned on a common ATC dataset. The word boosting is done in three ways. First, an out-of-vocabulary word addition method is explored. Second, G-boosting is explored, which amends the language model before building the decoding graph. Third, the boosting is performed on the fly during decoding using lattice re-scoring. The results indicate that the G-boosting method performs best and provides an approximately 30-43% relative improvement in recall of the boosted words. Moreover, a relative improvement of up to 48% is obtained upon combining G-boosting and lattice-rescoring.
@inproceedings{Bhattacharjee_ICASSP_2024,author={Bhattacharjee, Mrinmoy and Iuliia, Nigmatulina and Prasad, Amrutha and Rangappa, Pradeep and Madikeri, Srikanth and Motlicek, Petr and Helmke, Hartmut and Kleinert, Matthias},title={Contextual Biasing Methods for Improving Rare Word Detection in Automatic Speech Recognition},booktitle={Proc. 49th IEEE Int. Conf. on Acoustics, Speech, & Signal Process. (ICASSP)},projects={Idiap},month={Apr},year={2024},location={Seoul, Korea},}
Customization of Automatic Speech Recognition Engines for Rare Word Detection Without Costly Model Re-Training
Mrinmoy Bhattacharjee, Petr Motlicek, Iuliia Nigmatulina, Helmke Hartmut, Ohneiser Oliver, Kleinert Matthias, Ehr Heiko
13th SESAR Innovation Days 2023
[+Abs]
[HTML]
[PDF]
[+Bibtex]
Thanks to Alexa, Siri or Google Assistant automatic speech recognition (ASR) has changed our daily life during the last decade. Prototypic applications in the air traffic management (ATM) domain are available. Recently pre-filling radar label entries by ASR support has reached the technology readiness level before industrialization (TRL6). However, seldom spoken and airspace related words relevant in the ATM context remain a challenge for sophisticated applications. Open-source ASR toolkits or large pre-trained models for experts – allowing to tailor ASR to new domains – can be exploited with a typical constraint on availability of certain amount of domain specific training data, i.e., typically transcribed speech for adapting acoustic and/or language models. In general, it is sufficient for a “universal” ASR engine to reliably recognize a few hundred words that form the vocabulary of the voice communications between air traffic controllers and pilots. However, for each airport some hundred dependent words that are seldom spoken need to be integrated. These challenging word entities comprise special airline designators and waypoint names like “dexon” or “burok”, which only appear in a specific region. When used, they are highly informative and thus require high recognition accuracies. Allowing plug and play customization with a minimum expert manipulation assumes that no additional training is required, i.e., fine-tuning the universal ASR. This paper presents an innovative approach to automatically integrate new specific word entities to the universal ASR system. The recognition rate of these region-specific word entities with respect to the universal ASR increases by a factor of 6.
@article{bhattacharjee2023customization,author={Bhattacharjee, Mrinmoy and Motlicek, Petr and Nigmatulina, Iuliia and Helmke, Hartmut and Ohneiser, Oliver and Kleinert, Matthias and Ehr, Heiko},title={Customization of Automatic Speech Recognition Engines for Rare Word Detection Without Costly Model Re-Training},journal={13th SESAR Innovation Days},year={2023}}
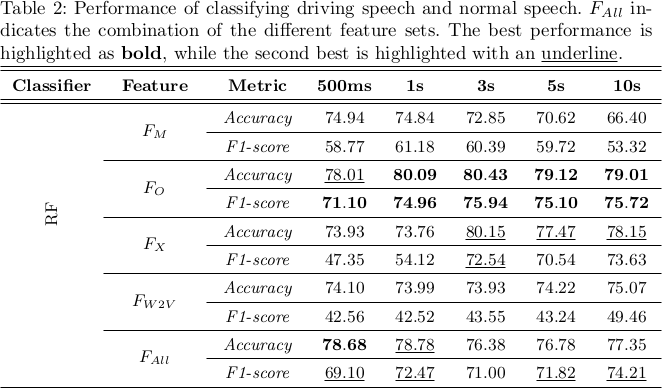
Driver Speech Detection in Real Driving Scenario
Mrinmoy Bhattacharjee, Shikha Baghel and S. R. Mahadeva Prasanna
25th International Conference on Speech and Computer
[+Abs]
[HTML]
[PDF]
[+Bibtex]
Abstract: Developing high-quality artificial intelligence based driver assistance systems is an active research area. One critical challenge is developing efficient methods to detect a driver speaking while driving. The availability of such methods would be vital in implementing safety features like blocking phone calls during driving, stress management of drivers, and other voice-based assistance applications. The present work tackles the While-Driving Speech (WDS) detection problem and makes three principal contributions. The first contribution is the creation of a manually annotated speech dataset curated from car review videos that consist of actual (non-acted) WDS data. Secondly, this work analyzes the effect of cognitively overloaded situations like driving on the prosodic characteristics of speech. Lastly, benchmark performances on the newly created dataset using standard speech classification approaches in detecting WDS are reported. This work is expected to spark interest in the community to explore this problem and develop more creative solutions.
@inproceedings{bhattacharjee2023driver,author={Bhattacharjee, Mrinmoy and Baghel, Shikha and Prasanna, SR Mahadeva},title={{Driver Speech Detection in Real Driving Scenario}},booktitle={Proc. Int. Conf. on Speech and Computer},pages={189-199},year={2023},organization={Springer}}
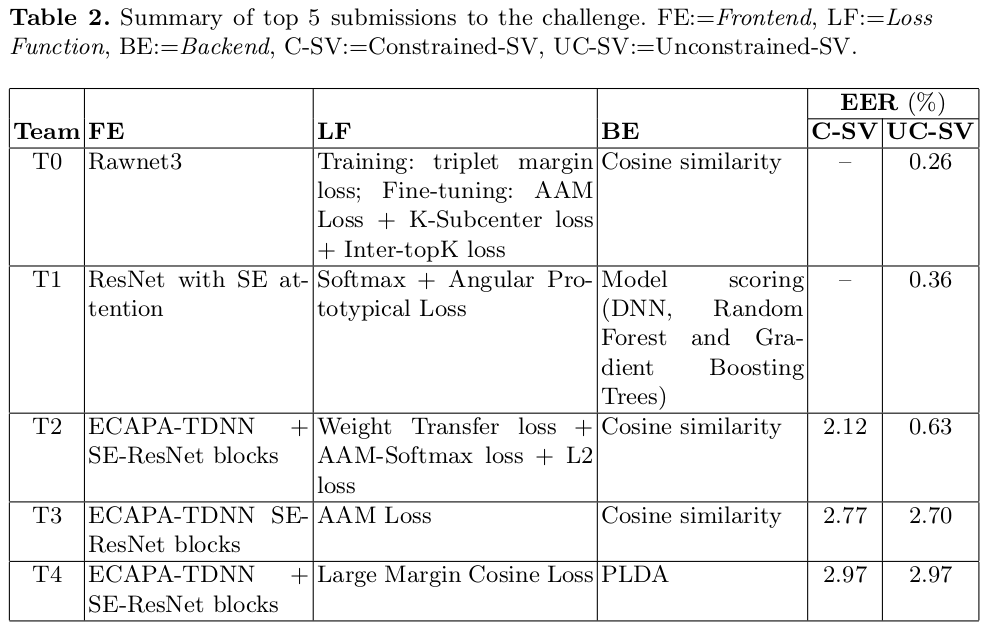
I-MSV 2022: Indic-Multilingual and Multi-sensor Speaker Verification Challenge
Jagabandhu Mishra, Mrinmoy Bhattacharjee and S. R. Mahadeva Prasanna
25th International Conference on Speech and Computer
[+Abs]
[HTML]
[PDF]
[+Bibtex]
Abstract: Speaker Verification (SV) is a task to verify the claimed identity of the claimant using his/her voice sample. Though there exists an ample amount of research in SV technologies, the development concerning a multilingual conversation is limited. In a country like India, almost all the speakers are polyglot in nature. Consequently, the development of a Multilingual SV (MSV) system on the data collected in the Indian scenario is more challenging. With this motivation, the Indic-Multilingual Speaker Verification (I-MSV) Challenge 2022 was designed to understand and compare the state-of-the-art SV techniques. An overview of the challenge and its outcomes is given here. For the challenge, approximately 100 hours of data spoken by 100 speakers were collected using 5 different sensors in 13 Indian languages. The data is divided into development, training, and testing sets and has been made publicly available for further research. The goal of this challenge is to make the SV system robust to language and sensor variations between enrollment and testing. In the challenge, participants were asked to develop the SV system in two scenarios, viz. constrained and unconstrained. The best system in the constrained and unconstrained scenario achieved a performance of 2.12% and 0.26% in terms of Equal Error Rate (EER), respectively.
@inproceedings{mishra2023msv,author={Mishra, Jagabandhu and Bhattacharjee, Mrinmoy and Prasanna, SR Mahadeva},title={{I-MSV 2022: Indic-Multilingual and Multi-sensor Speaker Verification Challenge}},booktitle={Proc. Int. Conf. on Speech and Computer},pages={437-445},year={2023},organization={Springer}}
Speech/music classification using phase-based and magnitude-based features
Mrinmoy Bhattacharjee, S. R. Mahadeva Prasanna and Prithwijit Guha
Elsevier Speech Communication
[+Abs]
[HTML]
[+Bibtex]
Abstract: Detection of speech and music is an essential preprocessing step for many high-level audio-based applications like speaker diarization and music information retrieval. Researchers have previously used various magnitude-based features in this task. In comparison, the phase spectrum has received lesser attention. The phase of a signal is believed to carry non-trivial information that can help determine its audio class. This work explores three existing phase-based features for speech vs. music classification. The potential of phase information is highlighted through statistical significance tests and canonical correlation analyses. The proposed approach is benchmarked against four baseline magnitude-based feature sets. This work also contributes an annotated audio dataset named Movie - MUSNOMIX of 8 h and 20 min duration, comprising seven audio classes, including speech and music. The Movie - MUSNOMIX dataset and widely used public datasets like MUSAN, GTZAN, Scheirer–Slaney, and Muspeak have been used for performance evaluations. In combination with magnitude-based ones, phase-based features improve upon the baseline performance consistently for the datasets used. Moreover, various combinations of phase and magnitude-based features show satisfactory generalization capability over the two datasets. The performances of phase-based features in identifying speech and music signals corrupted with different environmental noise at various SNR levels are also reported. Last but not least, a preliminary study on the efficacy of phase-based features in segmenting continuous sequences of speech and music signals is also provided. The codes used in this work and the contributed dataset have been made freely available.
@article{BHATTACHARJEE202234,
author={Mrinmoy Bhattacharjee and S.R. {Mahadeva Prasanna} and Prithwijit Guha},
journal={Speech Communication},
title={Speech/music classification using phase-based and magnitude-based features},
volume={142},
pages={34-48},
year={2022},
issn={0167-6393},
doi={https://doi.org/10.1016/j.specom.2022.06.005}
}
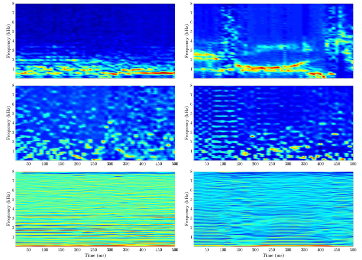
Clean vs. Overlapped Speech-Music Detection Using Harmonic-Percussive Features and Multi-Task Learning
Mrinmoy Bhattacharjee, S. R. Mahadeva Prasanna and Prithwijit Guha
IEEE/ACM Transactions on Audio, Speech, and Language Processing
[+Abs]
[HTML]
[PDF]
[+Bibtex]
Abstract: Detection of speech and music signals in isolated and overlapped conditions is an essential preprocessing step for many audio applications. Speech signals have wavy and continuous harmonics, while music signals exhibit horizontally linear and discontinuous harmonic patterns. Music signals also contain more percussive components than speech signals, manifested as vertical striations in the spectrograms. In case of speech music overlap, it might be challenging for automatic feature learning systems to extract class-specific horizontal and vertical striations from the combined spectrogram representation. A pre-processing step of separating the harmonic and percussive components before training might aid the classifier. Thus, this work proposes the use of harmonic-percussive source separation method to generate features for better detection of speech and music signals. Additionally, this work also explores the traditional and cascaded-information multi-task learning (MTL) frameworks to design better classifiers. MTL framework aids the training of the main task by employing simultaneous learning of several related auxiliary tasks. Results have been reported both on synthetically generated speech music overlapped signals and real recordings. Four state-of-the-art approaches are used for performance comparison. Experiments show that harmonic and percussive decomposition of spectrograms perform better as features. Moreover, the MTL-framework based classifiers further improve performances.
@article{9748030,
author={Bhattacharjee, Mrinmoy and Prasanna, S. R. M. and Guha, Prithwijit},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
title={Clean vs. Overlapped Speech-Music Detection Using Harmonic-Percussive Features and Multi-Task Learning},
year={2023},
volume={31},
number={},
pages={1-10},
doi={10.1109/TASLP.2022.3164199}
}
Speech Music Overlap Detection using Spectral Peak Evolutions
Mrinmoy Bhattacharjee, S. R. Mahadeva Prasanna and Prithwijit Guha
24th International Conference on Speech and Computer (SPECOM)
[+Abs]
[HTML]
[+Bibtex]
Abstract: Speech-music overlap detection in audio signals is an essential preprocessing step for many high-level audio processing applications. Speech and music spectrograms exhibit characteristic harmonic striations that can be used as a feature for detecting their overlap. Hence, this work proposes two features generated using a spectral peak tracking algorithm to capture prominent harmonic patterns in spectrograms. One feature consists of the spectral peak amplitude evolutions in an audio interval. The second feature is designed as a Mel-scaled spectrogram obtained by suppressing non-peak spectral components. In addition, a one-dimensional convolutional neural network architecture is proposed to learn the temporal evolution of spectral peaks. Mel-spectrogram is used as a baseline feature to compare performances. A popular public dataset MUSAN with 102 h of data has been used to perform experiments. A late fusion of the proposed features with baseline is observed to provide better performance.
@inproceedings{10.1007/978-3-031-20980-2_8,
author={Bhattacharjee, Mrinmoy and Prasanna, S. R. Mahadeva and Guha, Prithwijit},
title={Speech Music Overlap Detection Using Spectral Peak Evolutions},
booktitle={Speech and Computer},
year={2022},
publisher={Springer International Publishing},
address={Cham},
pages={75-86},
isbn={978-3-031-20980-2},
}
Foreground-Background Audio Separation using Spectral Peaks based Time-Frequency Masks
Mrinmoy Bhattacharjee, S. R. Mahadeva Prasanna and Prithwijit Guha
2022 IEEE International Conference on Signal Processing and Communications (SPCOM)
[+Abs]
[HTML]
[+Bibtex]
Abstract: The separation of foreground and background sounds can serve as a useful preprocessing step when dealing with real-world audio signals. This work proposes a foreground-background audio separation (FBAS) algorithm that uses spectral peak information for generating time-frequency masks. The proposed algorithm can work without training, is relatively fast, and provides decent audio separation. As a specific use case, the proposed algorithm is used to extract clean foreground signals from noisy speech signals. The quality of foreground speech separated with FBAS is compared with the output of a state-of-the-art deep-learning-based speech enhancement system. Various subjective and objective evaluation measures are computed, which indicate that the proposed FBAS algorithm is effective.
@inproceedings{9840850,
author={Bhattacharjee, Mrinmoy and Prasanna, S. R. Mahadeva and Guha, Prithwijit},
booktitle={2022 IEEE International Conference on Signal Processing and Communications (SPCOM)},
title={Foreground-Background Audio Separation using Spectral Peaks based Time-Frequency Masks},
year={2022},
volume={},
number={},
pages={1-5},
doi={10.1109/SPCOM55316.2022.9840850}
}
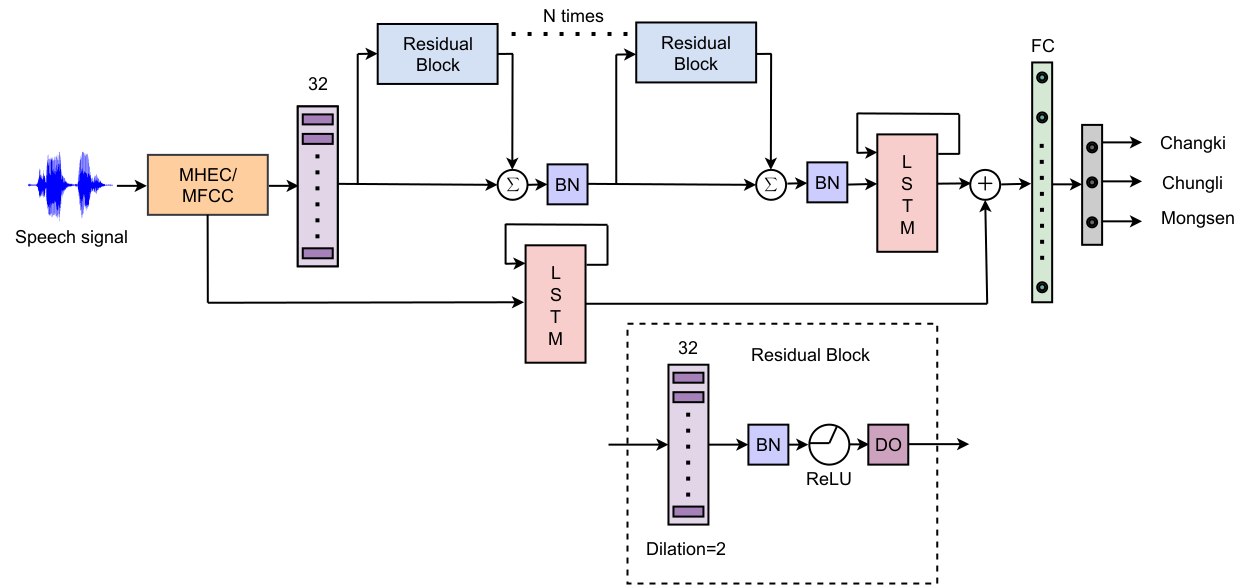
Low-Resource Dialect Identification in Ao Using Noise Robust Mean Hilbert Envelope Coefficients
Moakala Tzudir, Mrinmoy Bhattacharjee, Priankoo Sarmah, S. R. Mahadeva Prasanna
28th National Conference on Communications (NCC-2022)
[+Abs]
[HTML]
[+Bibtex]
Abstract: This paper presents an automatic dialect identification system in Ao using a deep Convolutional Neural Network with residual connections. Ao is an under-resourced language belonging to the Tibeto-Burman family in the North-East of India. The three distinct dialects of the language are Chungli, Mongsen and Changki. Ao is a tone language and consists of three tones, viz., high, mid, and low. The recognition of tones is said to be influenced by the production process as well as human perception. In this work, the Mean Hilbert Envelope Coefficients (MHEC) feature is explored to identify the three dialects of Ao as this feature is reported to have information of human auditory nerve responses. Mel Frequency Cepstral Coefficients (MFCC) feature is used as the baseline. In addition, the effect of noise in the dialect identification task at various signal-to-noise ratio scenarios is studied. The experiments show that the MHEC feature provides an improvement of almost 10% average F1-score at high noise cases.
@inproceedings{9806808,
author={Tzudir, Moakala and Bhattacharjee, Mrinmoy and Sarmah, Priyankoo and Prasanna, S. R. M.},
booktitle={2022 National Conference on Communications (NCC)},
title={Low-Resource Dialect Identification in Ao Using Noise Robust Mean Hilbert Envelope Coefficients},
year={2022},
volume={},
number={},
pages={256-261},
doi={10.1109/NCC55593.2022.9806808}
}
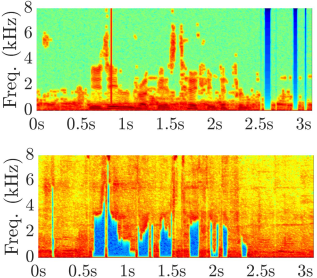
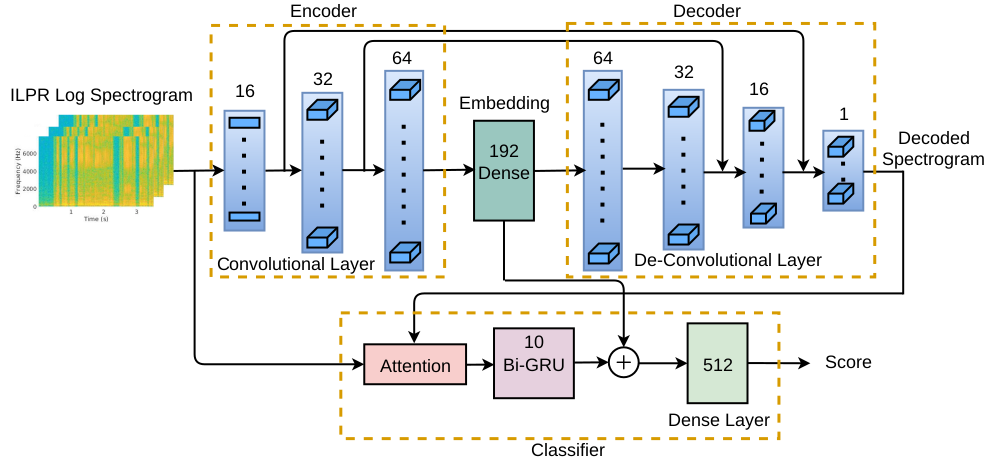
Automatic Detection of Shouted Speech Segments in Indian News Debates
Shikha Baghel, Mrinmoy Bhattacharjee, S. R. Mahadeva Prasanna, and Prithwijit Guha
Interspeech 2021
[+Abs]
[HTML]
[PDF]
[+Bibtex]
Abstract: Shouted speech detection is an essential pre-processing step in conventional speech processing systems such as speech and speaker recognition, speaker diarization, and others. Excitation source plays an important role in shouted speech production. This work explores feature computed from the Integrated Linear Prediction Residual (ILPR) signal for shouted speech detection in Indian news debates. The log spectrogram of ILPR signal provides time-frequency characteristics of excitation source signal. The proposed shouted speech detection system is deep network with CNN-based autoencoder and attention-based classifier sub-modules. The Autoencoder sub-network aids the classifier in learning discriminative deep embeddings for better classification. The proposed classifier is equipped with attention mechanism and Bidirectional Gated Recurrent Units. Classification results show that the proposed system with excitation feature performs better than baseline log spectrogram computed from the pre-emphasized speech signal. A score-level fusion of the classifiers trained on the source feature and the baseline feature provides the best performance. The performance of the proposed shouted speech detection is also evaluated at various speech segment durations.
@inproceedings{baghel21_interspeech,
author={Shikha Baghel and Mrinmoy Bhattacharjee and S.R. Mahadeva Prasanna and Prithwijit Guha},
title={{Automatic Detection of Shouted Speech Segments in Indian News Debates}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={4179-4183},
doi={10.21437/Interspeech.2021-1592}
}
Detection of Speech Overlapped with Low-Energy Music using Pyknograms
Mrinmoy Bhattacharjee, S. R. Mahadeva Prasanna and Prithwijit Guha
27th National Conference on Communications (NCC-2021)
[+Abs]
[HTML]
[+Bibtex]
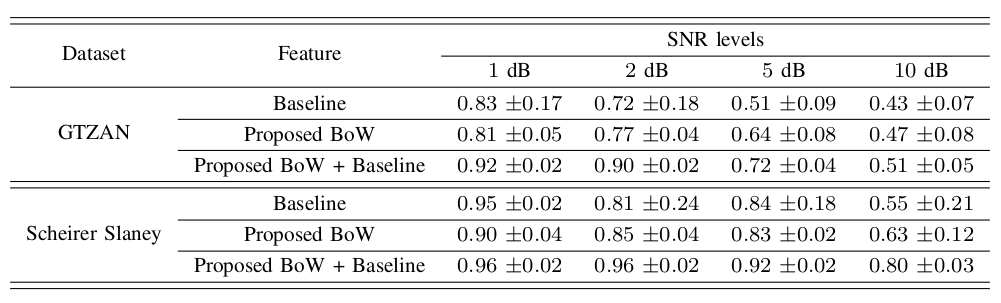
Abstract: Detection of speech overlapped with music is a challenging task. This work deals with discriminating clean speech from speech overlapped with low-energy music. The overlapped signals are generated synthetically. An enhanced spectrogram representation called Pyknogram has been explored for the current task. Pyknograms have been previously used in overlapped speech detection. The classification is performed using a neural network that is designed with only convolutional layers. The performance of Pyknograms at various high SNR levels is compared with that of discrete fourier transform based spectrograms. The classification system is benchmarked on three publicly available datasets, viz., GTZAN, Scheirer-slaney and MUSAN. The Pyknogram representation with the fully convolutional classifier performs well, both individually and in combination with spectrograms.
@inproceedings{9530150,
author={Bhattacharjee, Mrinmoy and Prasanna, S. R. Mahadeva and Guha, Prithwijit},
booktitle={2021 National Conference on Communications (NCC)},
title={Detection of Speech Overlapped with Low-Energy Music using Pyknograms},
year={2021},
volume={},
number={},
pages={1-6},
doi={10.1109/NCC52529.2021.9530150}
}
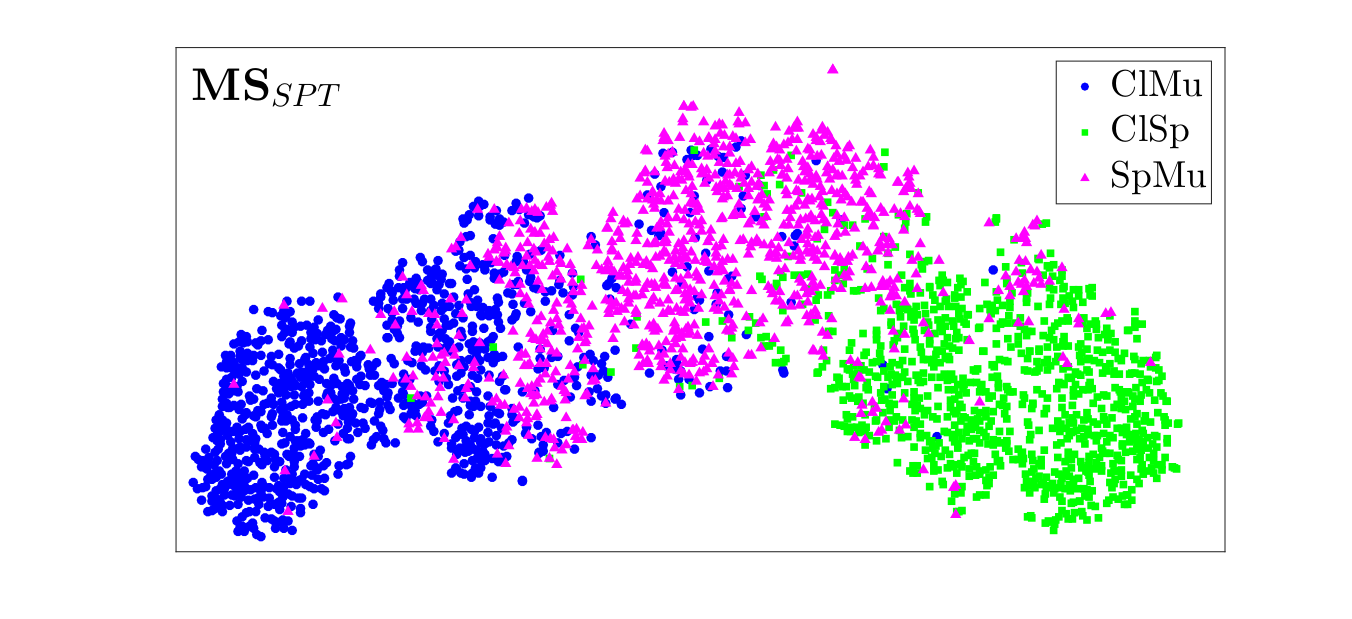
Speech/Music Classification Using Features From Spectral Peaks
Mrinmoy Bhattacharjee, S. R. Mahadeva Prasanna and Prithwijit Guha
IEEE/ACM Transactions on Audio, Speech, and Language Processing
[+Abs]
[HTML]
[PDF]
[+Bibtex]
Abstract: Spectrograms of speech and music contain distinct striation patterns. Traditional features represent various properties of the audio signal but do not necessarily capture such patterns. This work proposes to model such spectrogram patterns using a novel Spectral Peak Tracking (SPT) approach. Two novel time-frequency features for speech vs. music classification are proposed. The proposed features are extracted in two stages. First, SPT is performed to track a preset number of highest amplitude spectral peaks in an audio interval. In the second stage, the location and amplitudes of these peak traces are used to compute the proposed feature sets. The first feature involves the computation of mean and standard deviation of peak traces. The second feature is obtained as averaged component posterior probability vectors of Gaussian mixture models learned on the peak traces. Speech vs. music classification is performed by training various binary classifiers on these proposed features. Three standard datasets are used to evaluate the efficiency of the proposed features for speech/music classification. The proposed features are benchmarked against five baseline approaches. Finally, the best-proposed feature is combined with two contemporary deep-learning based features to show that such combinations can lead to more robust speech vs. music classification systems.
@article{9089263,
author={Bhattacharjee, Mrinmoy and Prasanna, S. R. Mahadeva and Guha, Prithwijit},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
title={Speech/Music Classification Using Features From Spectral Peaks},
year={2020},
volume={28},
number={},
pages={1549-1559},
doi={10.1109/TASLP.2020.2993152}
}
Classification of Speech vs. Speech with Background Music
Mrinmoy Bhattacharjee, S. R. Mahadeva Prasanna and Prithwijit Guha
2020 IEEE International Conference on Signal Processing and Communications (SPCOM)
[+Abs]
[HTML]
[+Bibtex]
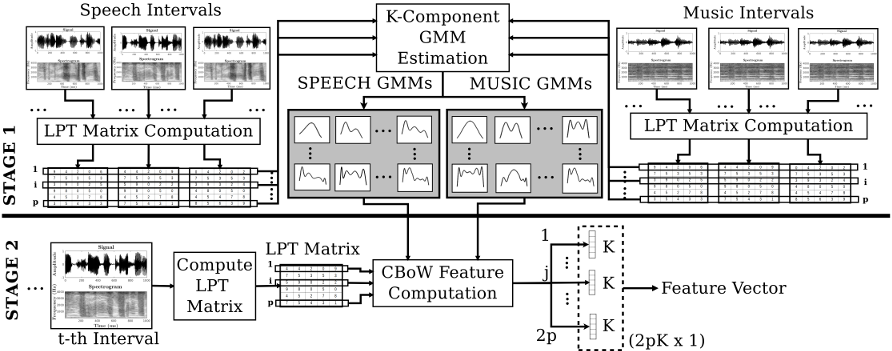
Abstract: Applications that perform enhancement of speech containing background music require a critical preprocessing step that can efficiently detect such segments. This work proposes such a preprocessing method to detect speech with background music that is mixed at different SNR levels. A bag-of-words approach is proposed in this work. Representative dictionaries from speech and music data are first learned. The signals are processed as spectrograms of 1s intervals. Rows of these spectrograms are used to learn separate speech and music dictionaries. This work proposes a weighting scheme to reduce confusion by suppressing codewords of one class that have similarities to the other class. The proposed feature is a weighted histogram of 1s audio intervals obtained from the learned dictionaries. The classification is performed using a deep neural network classifier. The proposed approach is validated against a baseline and benchmarked over two publicly available datasets. The proposed feature shows promising results, both individually and in combination with the baseline.
@inproceedings{9179491,
author={Bhattacharjee, Mrinmoy and Mahadeva Prasanna, S.R. and Guha, Prithwijit},
booktitle={2020 International Conference on Signal Processing and Communications (SPCOM)},
title={Classification of Speech vs. Speech with Background Music},
year={2020},
volume={},
number={},
pages={1-5},
doi={10.1109/SPCOM50965.2020.9179491}
}
Shouted and Normal Speech Classification Using 1D CNN
Shikha Baghel, Mrinmoy Bhattacharjee, S. R. Mahadeva Prasanna, and Prithwijit Guha
8th International Conference on Pattern Recognition and Machine Intelligence
[+Abs]
[HTML]
[+Bibtex]
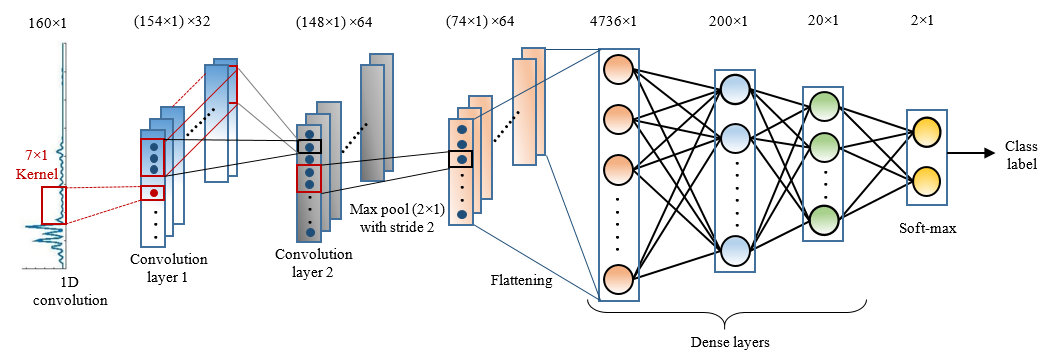
Abstract: Automatic shouted speech detection systems usually model its spectral characteristics to differentiate it from normal speech. Mostly hand-crafted features have been explored for shouted speech detection. However, many works on audio processing suggest that approaches based on automatic feature learning are more robust than hand-crafted feature engineering. This work re-demonstrates this notion by proposing a 1D-CNN architecture for shouted and normal speech classification task. The CNN learns features from the magnitude spectrum of speech frames. Classification is performed by fully connected layers at later stages of the network. Performance of the proposed architecture is evaluated on three datasets and validated against three existing approaches. As an additional contribution, a discussion of features learned by the CNN kernels is provided with relevant visualizations.
@inproceedings{10.1007/978-3-030-34872-4_52,
author={Baghel, Shikha and Bhattacharjee, Mrinmoy and Prasanna, S. R. M. and Guha, Prithwijit},
title={Shouted and Normal Speech Classification Using 1D CNN},
booktitle={Pattern Recognition and Machine Intelligence},
year={2019},
publisher={Springer International Publishing},
address={Cham},
pages={472-480},
isbn={978-3-030-34872-4}
}
Determining redundant nodes in a location unaware Wireless Sensor Network
Mrinmoy Bhattacharjee and Subhrata Gupta
2012 IEEE International Conference on Advanced Communication Control and Computing Technologies (ICACCCT)
[+Abs]
[HTML]
[+Bibtex]
Abstract: Recently Wireless Sensor Networks (WSNs) have garnered a great interest among the research community. WSNs are heavily energy constrained and hence redundant nodes in the network must be allowed to sleep so that the network lifetime may be enhanced. Recently a lot of work has been done to determine the amount of redundancy inherent in a WSN. This paper describes a method that attempts to reduce the redundancy in the network that is distributive in nature and does not use the location information of the nodes. To find out if a node is redundant, the nodes' sensing area overlap is to be found out. The method uses three-circle overlap area as the base case for finding the total overlap over the sensing area of a node by its neighbors. The work here is for static deployment of the sensor nodes.
@inproceedings{7019215,
author={Bhattacharjee, Mrinmoy and Gupta, S.},
booktitle={2014 IEEE International Conference on Advanced Communications, Control and Computing Technologies},
title={Determining redundant nodes in a location unaware Wireless Sensor Network},
year={2014},
volume={},
number={},
pages={858-862},
doi={10.1109/ICACCCT.2014.7019215}
}